Month: April 2022

PaySend Invite code: 0d8425
Posted by Alex On April 22, 2022

What happens if an IPv4 client tries to access an IPv6-only server (SOLVED)
Posted by Alex On April 9, 2022

How to edit the Access denied page in Squid? How to insert custom pictures and mail?
Posted by Alex On April 7, 2022
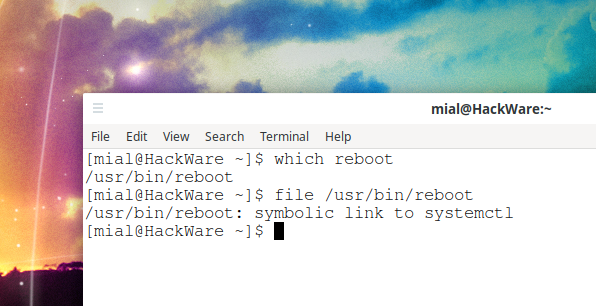
What is the difference between “systemctl reboot” and “reboot” and “systemctl poweroff” and “poweroff”
Posted by Alex On April 6, 2022
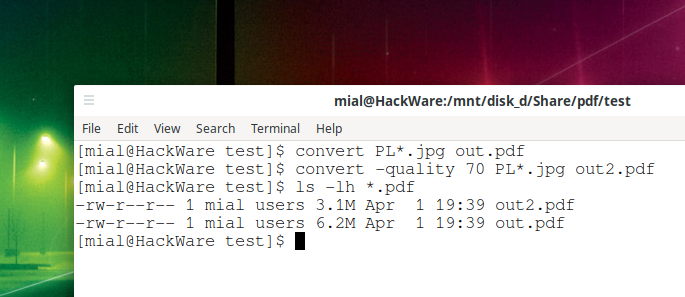
How to convert JPG to PDF
Posted by Alex On April 3, 2022

How to convert PDF to JPG using command line in Linux (SOLVED)
Posted by Alex On April 2, 2022