
How to protect my website from bots
August 19, 2021
In the article “How to block by Referer, User Agent, URL, query string, IP and their combinations in mod_rewrite” I showed how to block requests to a site that match several parameters at once – on the one hand, it is effective against bots, on the other – practically eliminates false positives, that is, when a regular user who is not related to bots.
It is not difficult to block bots, it is difficult to find their patterns that expose the request from the bot. There should have been another part in that article, in which I showed exactly how I assembled these patterns. I wrote it, took screenshots, but ultimately didn't add it to the article. Not because I am greedy, but I just thought that this was at odds with the topic of an article that was not the easiest one, and, in fact, very few people are interested in it.
But the day before yesterday, bots started an attack on my other site, I decided to take action against the bot… I forgot how I was collecting data)))) In general, so as not to invent commands every time, now they will be stored here)) You might find this useful too.
How to know that a site has become a target for bots
The first sign is a sharp and unreasonable increase in traffic. This was the reason to go to Yandex.Metrica statistics and check “Reports” → “Standard reports” → “Sources” → “Sources, summary”:
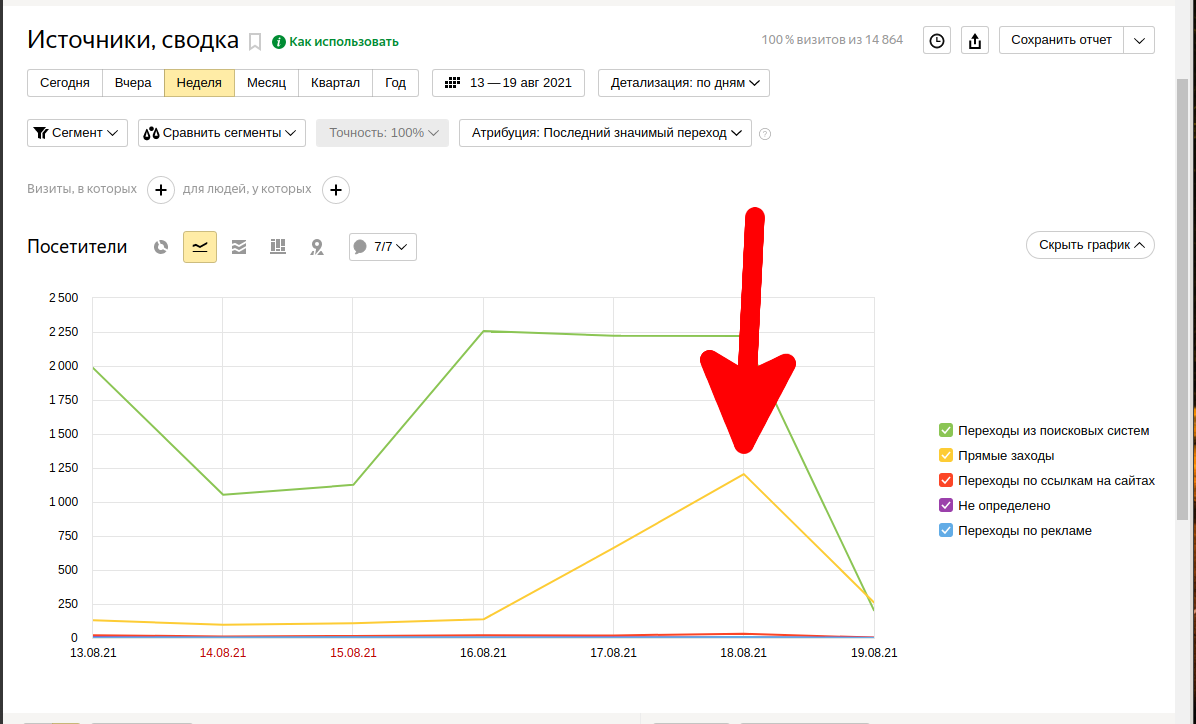
Yes, there is a sharp surge in direct visits, and today there are even more of them than traffic from search engines.
Let's look at Webivisor:
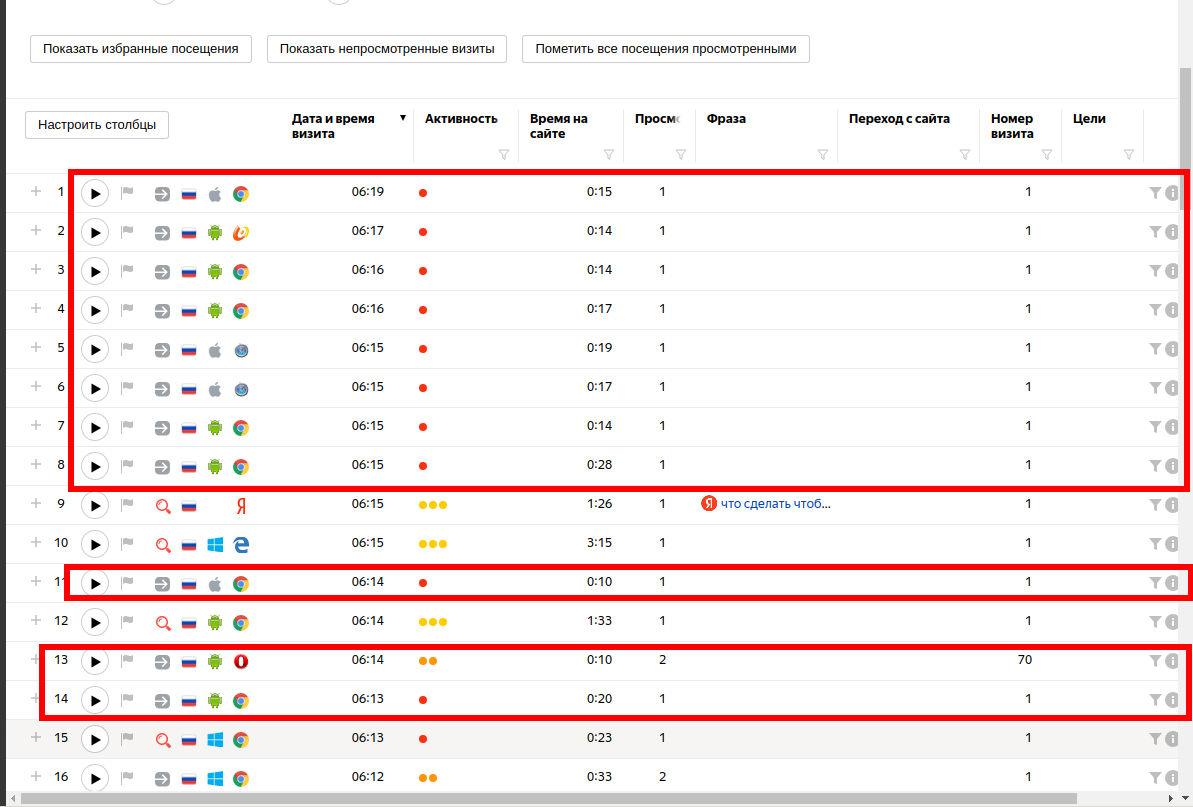
Short sessions from mobile devices, strange User Agents (includes very old devices), specific nature of the region/ISP. Yes, these are bots.
Identifying of IP addresses of the bots
Let's look at the command:
cat site.ru/logs/access_log | grep '"-"' | grep -E -i 'android|iPhone' | grep -i -E -v 'google|yandex|petalbot' | awk '{ print $1 }' | sort | uniq -c
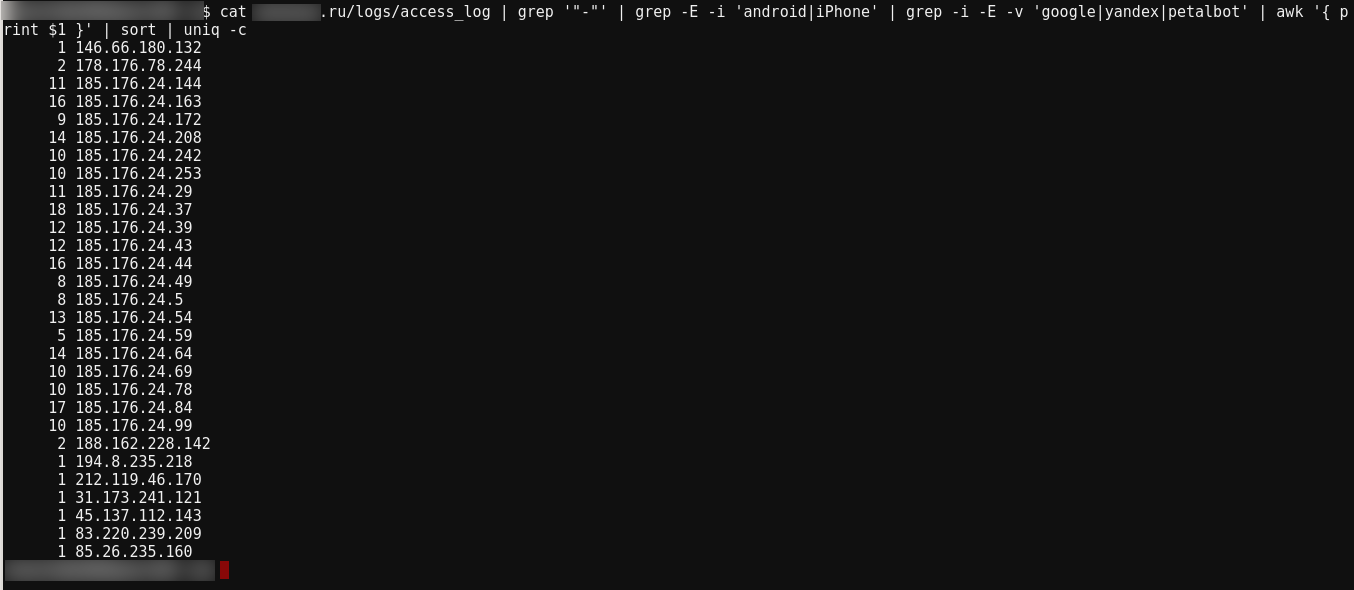
In it:
- cat site.ru/logs/access_log — read the web server log file
- grep '"-"' — we filter requests, leaving only with an empty referrer
- grep -E -i 'android|iPhone' — filter requests, leaving only mobile ones
- grep -i -E -v 'google|yandex|petalbot' — remove requests from specified web crawlers
- awk '{ print $1 }' — leave only the IP address (first field)
- sort | uniq -c — sort and leave unique ones, display the quantity
In my opinion, everything is pretty obvious, all requests come from the same subnet 185.176.24.0/24.
But now is morning, there is still little data, let's check the log of the web server for yesterday:
zcat site.ru/logs/access_log.1 | grep '"-"' | grep -E -i 'android|iPhone' | grep -i -E -v 'google|yandex|petalbot' | awk '{ print $1 }' | sort | uniq -c
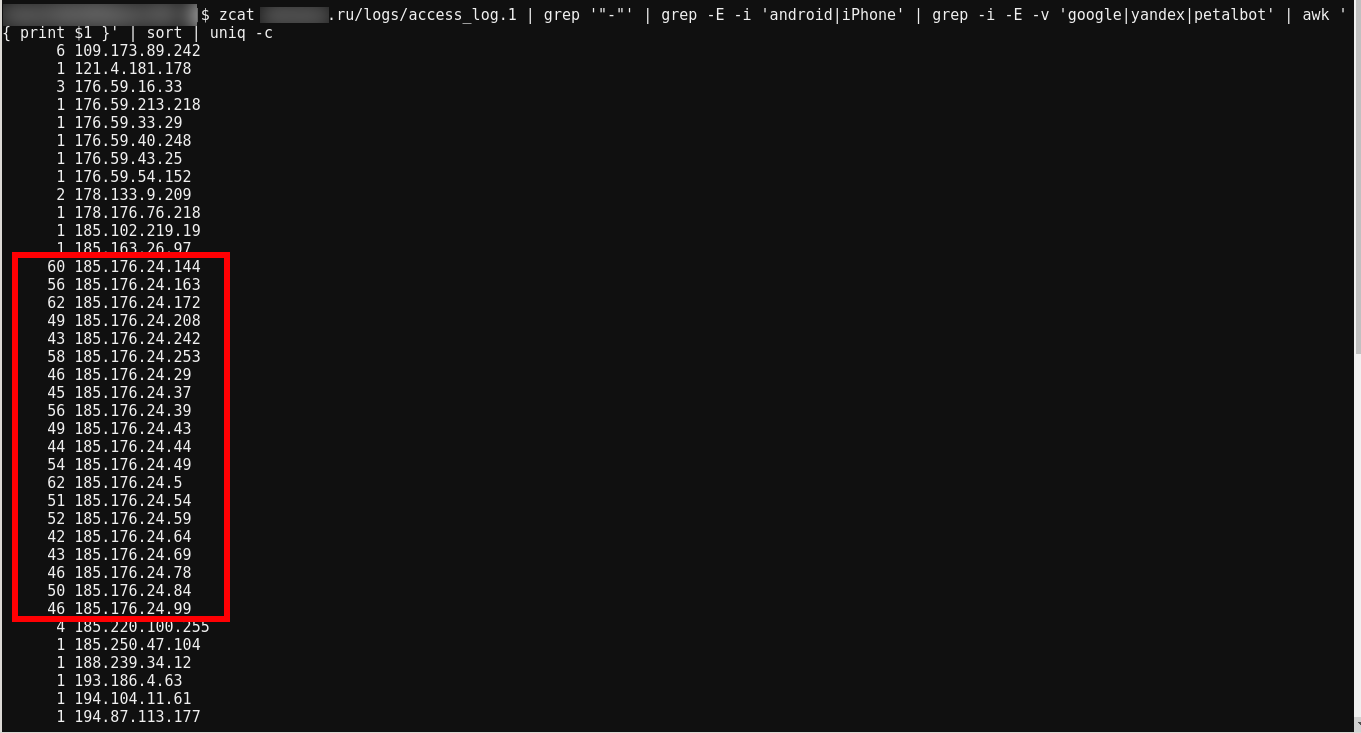
Yes, all bots came from the 185.176.24.0/24 network.
Basically, you can just block this entire subnet and end up there. But it is better to continue collecting data, then I will explain why.
Let's see which pages the bots are requesting:
cat site.ru/logs/access_log | grep '"-"' | grep -E -i 'android|iPhone' | grep -i -E -v 'google|yandex|petalbot' | grep '185.176.24' | awk '{ print $7 }' | sort | uniq -c
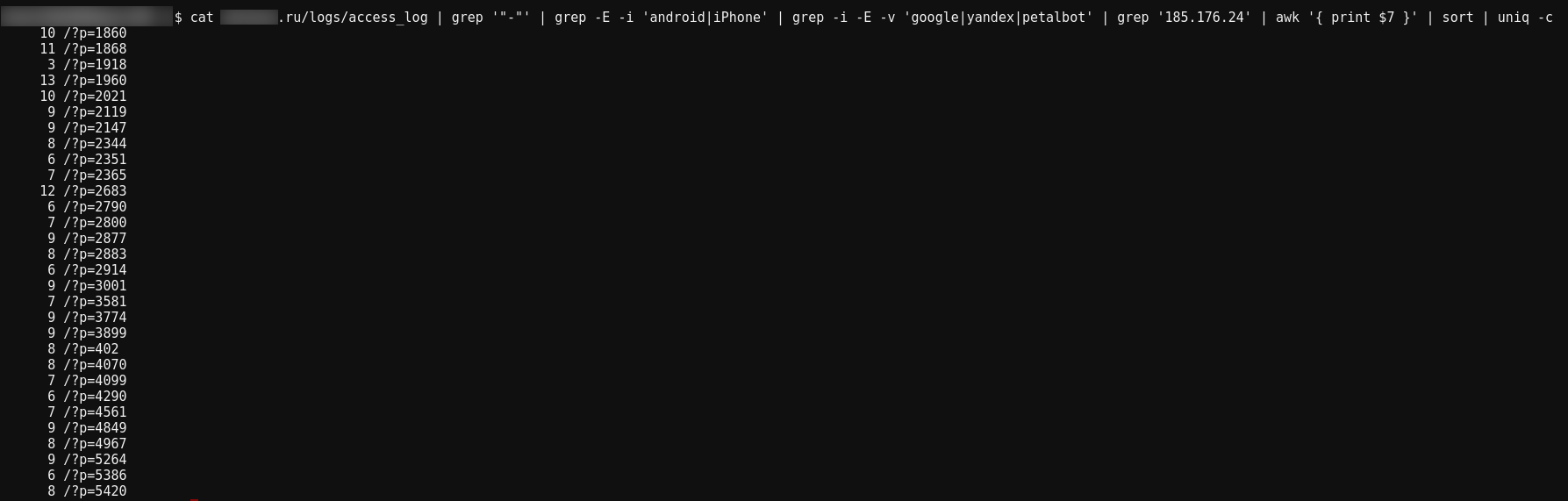
zcat site.ru/logs/access_log.1 | grep '"-"' | grep -E -i 'android|iPhone' | grep -i -E -v 'google|yandex|petalbot' | grep '185.176.24' | awk '{ print $7 }' | sort | uniq -c
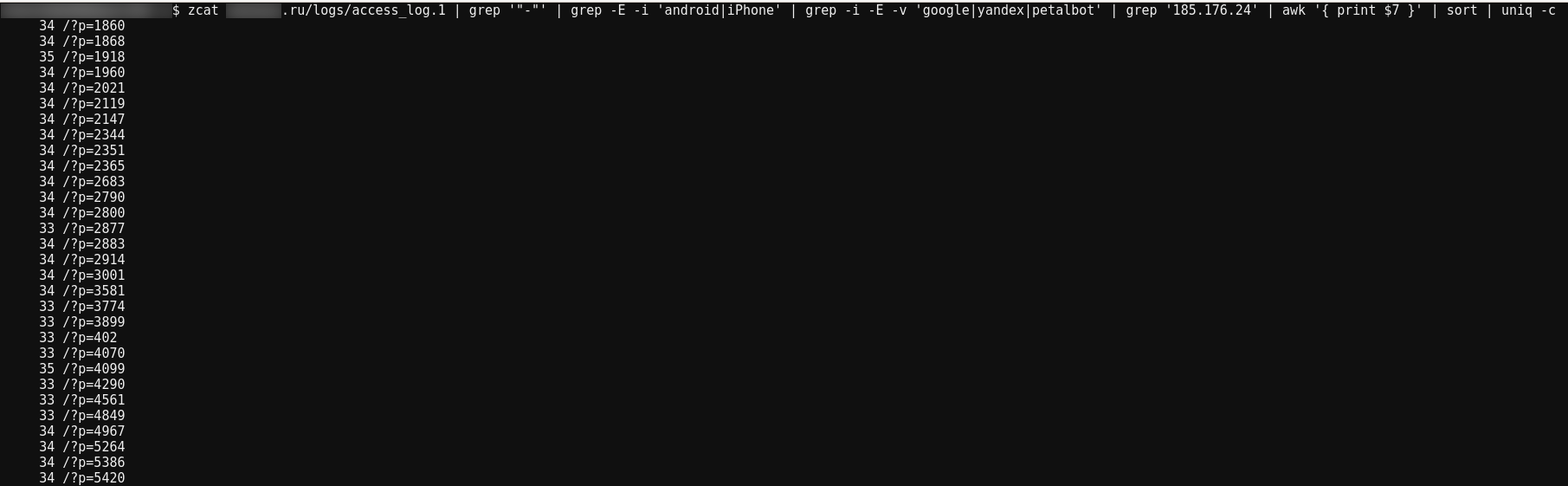
These commands have new parts:
- grep '185.176.24' — filter for requests from the attacker's network
- awk '{ print $7 }' — the requested page in my server logs is the seventh column
The bot requests exactly 30 pages.
We return to the article “How to block by Referer, User Agent, URL, query string, IP and their combinations in mod_rewrite” and block the bot.
But in my case, I can get by with blocking the subnet.
In Apache 2.4:
<RequireAll> Require all granted Require not ip 185.176.24 </RequireAll>
In Apache 2.2:
Deny from 185.176.24
Keep your finger on the pulse
This is not the first influx of bots that I've been fighting, and you need to remember that the owner of bots changes the bot settings after your actions. For example, the previous time it all started with the following pattern:
- bots requested 5 specific pages
- all bots were with Android user agent
- came from a specific set of mobile operator networks
- empty referrer
After I blocked on these grounds, the owner of bots changed the behavior of the bots:
- added URL (now 8 pages)
- iPhone added as User-Agent
- the number of subnets increased, but bots still came only from mobile operators
I blocked them too. After that, the bot engine added desktops to the user agents, but all other patterns remained the same, so I successfully blocked it.
After that, the bot owner did not change the behavior of the bots, and after some time (a week or two) the bots stopped trying to enter the site, I deleted the blocking rules.
For further analysis
The command for filtering requests from the specified subnet (185.176.240/24), which have a response code of 200 (that is, not blocked) – useful in case bots change the User Agent:
cat site.ru/logs/access_log | grep '"-"' | grep -E -i 'android|iPhone' | grep -i -E -v 'google|yandex|petalbot' | grep '185.176.24' | grep ' 200 ' | tail -n 10
A variant of the command for compiling a list of IP addresses given at the beginning of this article, but only requests with a response code 200 are taken into account in the command (those that we have already blocked are filtered out):
cat site.ru/logs/access_log | grep '"-"' | grep -E -i 'android|iPhone' | grep -i -E -v 'google|yandex|petalbot' | grep ' 200 ' | awk '{ print $1 }' | sort | uniq -c
Command for monitoring the latest requests specific to bots:
cat site.ru/logs/access_log | grep '"-"' | grep -E -i 'android|iPhone' | grep -i -E -v 'google|yandex|petalbot' | tail -n 10
How the influx of bots affects the site
This time, I reacted pretty quickly – a day after the attack started. But the last time bots walked around my site for a couple of weeks before I got tired of it. This did not have any impact on the position of the site in the search results.
Related articles:
- How to block by Referer, User Agent, URL, query string, IP and their combinations in mod_rewrite (100%)
- How to check if my router supports IPv6 (51.2%)
- Script to connect and disconnect from OpenVPN depending on server availability (51.2%)
- What happens if an IPv4 client tries to access an IPv6-only server (SOLVED) (51.2%)
- “Failed - Network error” when exporting from phpMyAdmin (SOLVED) (50.6%)
- How to enable saving photos in HEIC (HEIF) format in Android and whether it should be done (RANDOM - 27.2%)