How to remove newline from command output and files on Linux command line
July 8, 2022
How to remove newline from a string in Bash
The following characters are used for line breaks in operating systems:
- '\n' (newline)
- '\r' (carriage return)
Moreover, \n is used in Linux (also called EOL, End of Line, newline). There may be variations on other operating systems.
By default, many programs, Linux command line utilities automatically add the newline character – in general, this makes the output more readable. But sometimes the newline character is not needed. This note is about how to remove the newline character from the output string or from the lines of the file.
How to remove newline character from a string
echo
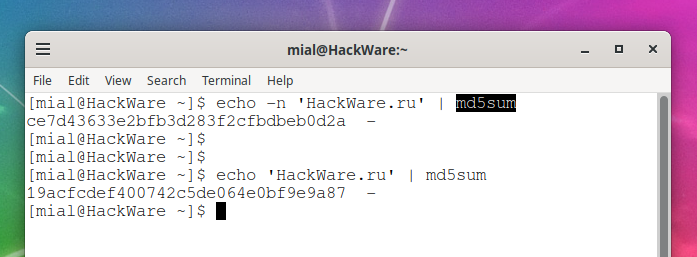
If you're echoing a string or the result of a command with “echo”, then you can use the -n option, which means don't print the trailing newline character.
Note the different output of the commands:
echo -n 'HackWare.ru' | md5sum ce7d43633e2bfb3d283f2cfbdbeb0d2a - echo 'HackWare.ru' | md5sum 19acfcdef400742c5de064e0bf9e9a87 -
The first command calculates the checksum of the “HackWare.ru” string, and the second command calculates the checksum of the “HackWare.ru” string to which the trailing newline character is added.
tr
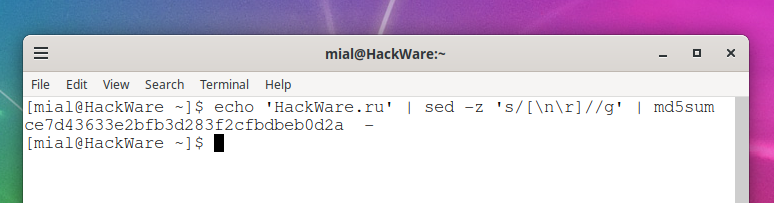
You can remove the trailing newline with tr in the construct
tr -d '\n'
For example:
echo 'HackWare.ru' | tr -d '\n' | md5sum ce7d43633e2bfb3d283f2cfbdbeb0d2a -
sed
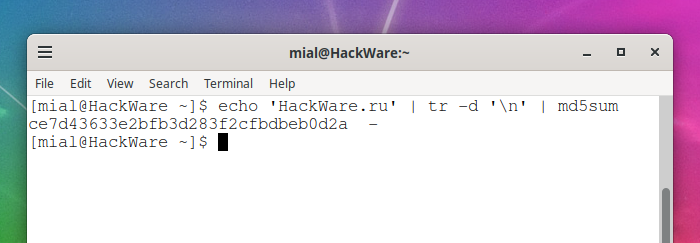
You can remove the trailing newline with sed in a construct (this command removes the "\n" and "\r" characters:
sed -z 's/[\n\r]//g'
For example:
echo 'HackWare.ru' | sed -z 's/[\n\r]//g' | md5sum ce7d43633e2bfb3d283f2cfbdbeb0d2a -
Perl
The following PERL construct also removes the newline character:
perl -pe 'chomp'
Example:
echo 'HackWare.ru' | perl -pe 'chomp' | md5sum ce7d43633e2bfb3d283f2cfbdbeb0d2a -
Another usage example:
wc -l < log.txt | perl -pe 'chomp'
awk
With awk, you can remove newline characters using the following construct:
awk '{ printf "%s", $0 }'
For example:
echo 'HackWare.ru' | awk '{ printf "%s", $0 }' | md5sum
Another option:
awk '{printf $0}'
For example:
echo 'HackWare.ru' | awk '{printf $0}' | md5sum
Removing newline from command output
All previous examples can be used to remove newline from command output by piping the output (“|”). Here are a few more constructs that you can use to remove newline from the output of a command.
printf
Put the COMMAND in the expression:
printf '%s' $(COMMAND)
The result of executing the COMMAND without the trailing newline will be displayed.
For example:
printf '%s' $(echo 'HackWare.ru') | md5sum
xargs and echo
To suppress the output of the newline character, you can use the xargs construct:
COMMAND | xargs echo -n
Be careful with the previous construct as it also compresses spaces. To understand what is at stake, examine the output of the following command:
echo "a b" | xargs echo -n; echo -n $(echo "a b")
Because xargs can be very slow, you can use the following construct:
echo -n `COMMAND`
Remember that if the output starts with -e, then the previous construct will interpret the output as an “echo” option.
Command substitution
In the following examples, the command enclosed in "$(COMMAND)" will be printed without the trailing newline:
echo -n "$(wc -l < log.txt)" printf "%s" "$(wc -l < log.txt)"
How to remove only last newline character from multiline output
All previous examples assume that deleting a character is done from a single line output. If you need to remove the last character from a multiline output, the following shows how to do it.
Perl
The following command will output the contents of the log.txt file, removing only one newline character at the very end of the file, all other newlines will be preserved. The peculiarity of the command is that even if the file ends with several newline characters, they will all be deleted.
perl -pe 'chomp if eof' log.txt
printf
The following example will also remove the newline character at the end of the log.txt file, but it will only remove the LAST newline character:
printf "%s" "$(< log.txt)"
How to remove newline from a file in Bash
You can use file output in conjunction with any of the above constructs to remove the newline. For example:
cat log.txt | tr -d '\n'
Similar to the previous command:
tr -d '\n' < log.txt
The awk, sed, perl, and other commands can either process standard input or take the names of the file to be processed (remove newlines) as an option. Examples:
awk '{ printf "%s", $0 }' log.txt
awk '{printf $0}' file
sed ':a;N;$!ba;s/\n//g' file.txt
perl -p -i -e 's/\R//g;' filename
How to remove newline from a variable in Bash
To remove the newline character (or any other characters) you can use Pattern substitution (a kind of Shell Parameter Expansion), the format is as follows:
- To remove all matches:
${VARIABLE//FROM/TO}
- To remove the first match:
${VARIABLE/FROM/TO}
- To remove a match at the end of a string:
${VARIABLE/%FROM/TO}
- Removing all matches and assigning a new value to the same variable:
VARIABLE=${VARIABLE//FROM/TO}
In this case, the newline character (\n) must be escaped with a backslash.
Variable output without removing newline:
text='hello\n\nthere\nagain\n'
echo -e ${text}
Result:
hello there again
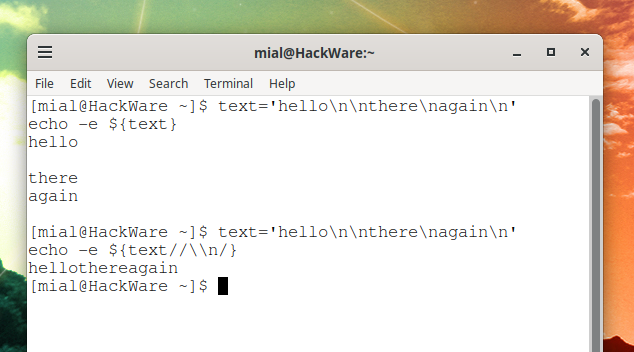
Variable output with all newlines removed:
text='hello\n\nthere\nagain\n'
echo -e ${text//\\n/}
Result:
hellothereagain
Variable output with only the first newline removed:
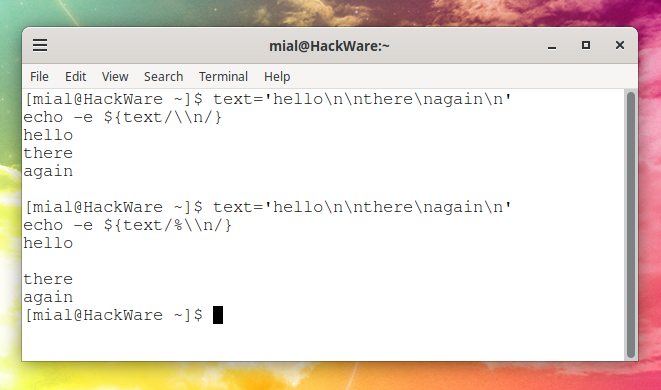
text='hello\n\nthere\nagain\n'
echo -e ${text/\\n/}
Result:
hello there again
Variable output with the last newline removed:
text='hello\n\nthere\nagain\n'
echo -e ${text/%\\n/}
Result:
hello there again
How to replace newline ("\n") with space (" ")
tr
To replace newline ("\n") with a space you can use the following construct:
tr '\n' ' '
For example:
echo -e 'hello\n\nthere\nagain\n' | tr '\n' ' '
sed
GNU sed:
sed ':a;N;$!ba;s/\n/ /g' FILE
Cross platform compatible syntax that works with BSD and OS X sed:
sed -e ':a' -e 'N' -e '$!ba' -e 's/\n/ /g' FILE
GNU sed has a -z option for zero-delimited entries (lines). You can simply call:
sed -z 's/\n/ /g'
Example:
sed -z 's/\n/ /g' FILE
Bash
Slow solution:
while read line; do printf "%s" "$line "; done < FILE
Another solution:
cat FILE.txt | while read line; do echo -n "$line "; done
One more solution:
while read line; do echo -n "$line "; done < FILE.txt
Perl
Perl solution, speed is about the same as with sed:
perl -p -e 's/\n/ /' FILE
paste
Solution with tr, speed is about the same as with paste, can only replace one character:
paste -s -d ' ' FILE
awk
Solution with awk, speed is about the same as with tr:
awk 1 ORS=' ' FILE
Explanation:
An awk program is made up of rules made up of conditional code blocks, that is:
condition { code block }
If the code block is omitted, the default value is used: { print $0 }. Thus, 1 is always interpreted as a true condition, and print $0 is executed for each line.
When awk reads input, it breaks it into records based on the RS (Record Separator) value, which is newline by default, so awk will parse the input line by line by default. The split also includes the removal of RS from the input record.
Now, when printing a record, ORS (Output Record Separator) is added to it, by default again newline. Thus, since we have replaced the ORS value with a space, all newlines are replaced with spaces.
Another option to replace all newlines with spaces using awk without reading the entire file into memory:
awk '{printf "%s ", $0}' FILE
If you want the final newline to be present:
awk '{printf "%s ", $0} END {printf "\n"}' FILE
You can use more than just the space character (in this case, instead of a space, the separator is the “|” character):
awk '{printf "%s|", $0} END {printf "\n"}' FILE
Another simple awk solution:
awk '{printf $0 " "}' FILE
xargs
Simple xargs solution:
xargs < FILE.txt
Related articles:
- How to convert a string to uppercase in Bash (89.4%)
- How to convert a string to lowercase in Bash (89.4%)
- How to print from specific column to last in Linux command line (81.4%)
- awk and tabs in input and output (73.4%)
- How to use Kali Linux to check web-sites (50%)
- How to reboot a server in DigitalOcean (RANDOM - 50%)