How to find and remove non-UTF-8 characters from a text file
March 14, 2021
Filtering invalid UTF-8 characters
Files that, in addition to ordinary characters, contain characters that are invalid from the UTF-8 point of view, cause a problem both when they are processed by utilities and when opened in text editors.
An example of an error in Python 3 when trying to process a file with non-UTF-8 characters:
[-] Exception as following:
Traceback (most recent call last):
File "/home/mial/bin/pydictor/lib/fun/decorator.py", line 21, in magic
for item in unique(func()):
File "/home/mial/bin/pydictor/lib/fun/fun.py", line 30, in unique
for item in seq:
File "/home/mial/bin/pydictor/tools/uniqifer.py", line 31, in uniqifer
for item in o_f.readlines():
File "/usr/lib/python3.9/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf1 in position 933: invalid continuation byte
None
An example of an error in Perl:
Malformed UTF-8 character (fatal)
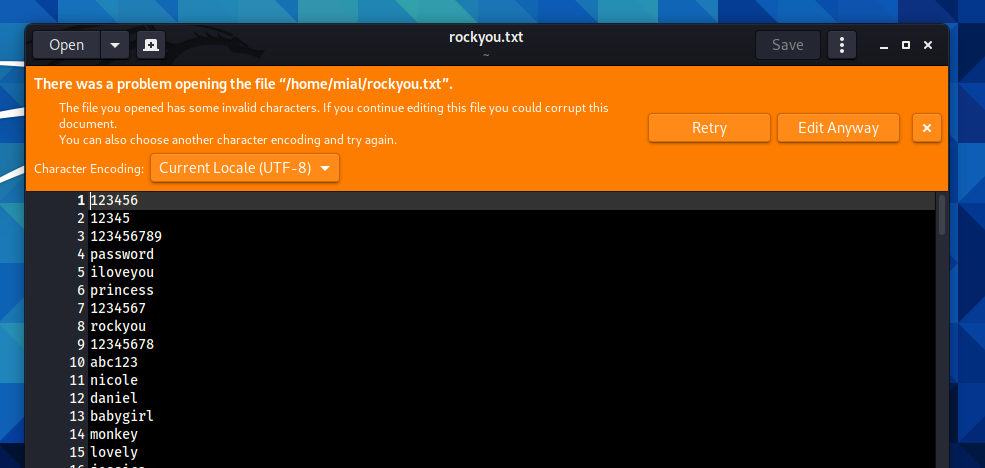
Sample message when trying to open in gedit text editor:
There was a problem opening the file. The file you opened has some invalid characters. If you continue editing this file you could corrupt this document. You can choose another character encoding and try again.
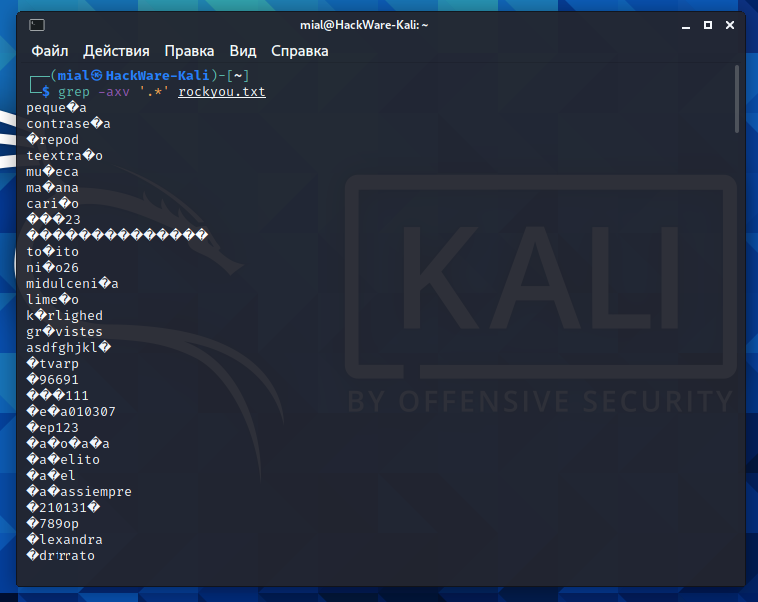
How to find non-UTF-8 characters in a file
To find lines with unreadable characters, use a command like this:
grep -axv '.*' FILE
In the UTF-8 locale, you will get strings containing at least one invalid UTF-8 sequence (at least this works with GNU Grep).
As you can see in the screenshot, there are indeed strange symbols.
If you check the contents of these files manually, you will also find some strange characters in them.
Is there a way to remove them all automatically?
What are non-UTF-8 characters?
You might think that all the characters in a well-formed UTF-8 string are UTF-8 (actually Unicode) characters! Some of them are UTF-8 encoded in several consecutive bytes.
But in fact, there are malformed UTF-8 characters. This means that a byte has appeared that cannot be part of a valid UTF-8 file. It is not difficult; it could be 0xC0 or 0xC1 byte, or 0xF5..0xFF, or a sequence problem with bytes that would otherwise be valid.
How to automatically remove garbled characters (not UTF-8) from a file
This command:
iconv -f utf-8 -t utf-8 -c FILE.txt
will clean up your UTF-8 file by skipping any invalid characters.
- -f - original format
- -t - target format
- -c - skips any invalid sequence
On Mac, use the command:
iconv -f utf-8 -t utf-8 -c file.txt
That is, a hyphen is needed between 'f' and '8'.
By default, the cleared data will be written to standard output. Therefore, use one of the following commands to save the results to a new file:
iconv -f utf-8 -t utf-8 -c FILE.txt -o NEW_FILE.txt iconv -f utf-8 -t utf-8 -c FILE.txt > NEW_FILE.txt
Examples:
iconv -f utf-8 -t utf-8 -c ~/rockyou.txt > ~/rockyou_clean.txt iconv -f utf-8 -t utf-8 -c ~/rockyou.txt -o ~/rockyou_clean.txt
Related articles:
- Analogue of the --force option in pacman (51.9%)
- How to downgrade to a previous kernel in Arch Linux (51.9%)
- bash: finger: command not found in Arch Linux (RESOLVED) (51.9%)
- How to choose the default Java version in Arch Linux (51.9%)
- VirtualBox shared folder is read-only (SOLVED) (51.9%)
- Errors “Incorrect definition of table mysql.event: expected column 'definer' at position 3 to have type varchar(, found type char(141)” and “Event Scheduler: An error occurred when initializing system tables. Disabling the Event Scheduler” (SOLVED) (RANDOM - 51.9%)