Tag: console text processing and console text editors
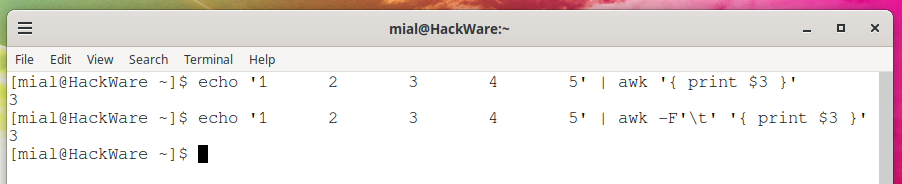
awk and tabs in input and output
Posted by Alex On July 9, 2022
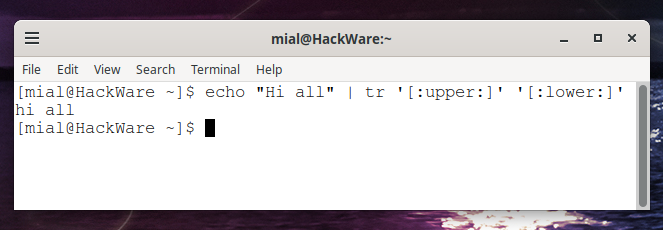
How to convert a string to lowercase in Bash
Posted by Alex On July 9, 2022
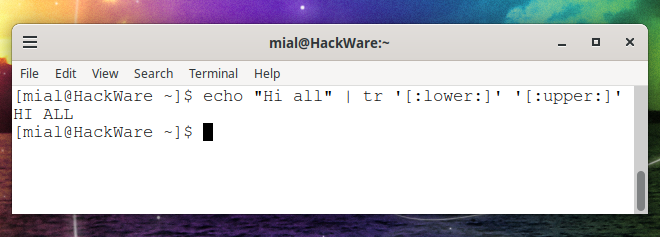
How to convert a string to uppercase in Bash
Posted by Alex On July 9, 2022

How to print from specific column to last in Linux command line
Posted by Alex On July 9, 2022
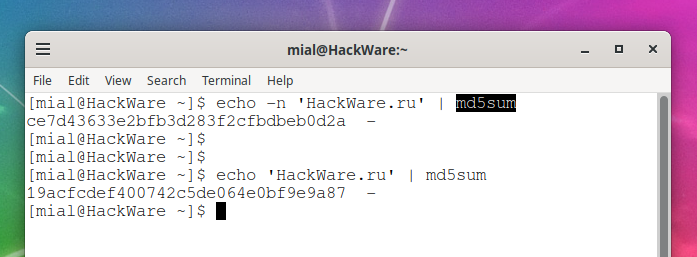
How to remove newline from command output and files on Linux command line
Posted by Alex On July 8, 2022