Tag: PDF
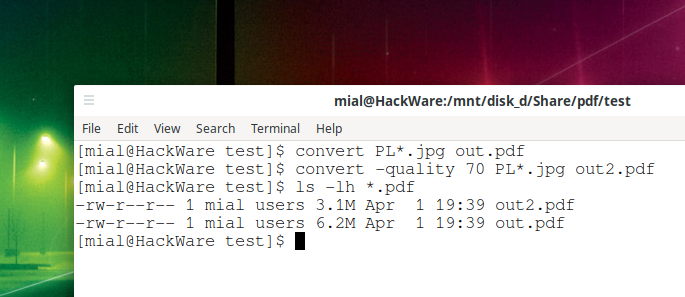
How to convert JPG to PDF
Posted by Alex On April 3, 2022

How to convert PDF to JPG using command line in Linux (SOLVED)
Posted by Alex On April 2, 2022
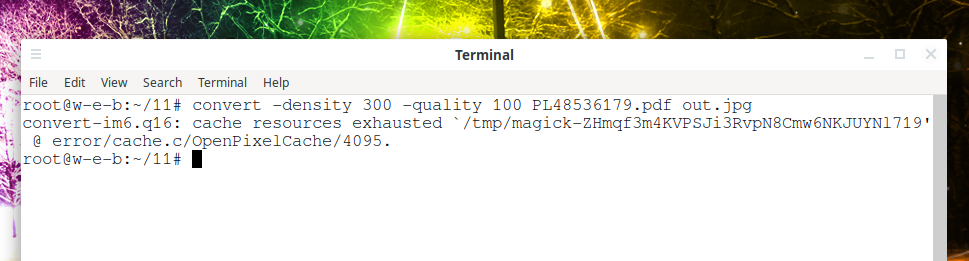
Error “convert: cache resources exhausted” (SOLVED)
Posted by Alex On March 22, 2022

Error “attempt to perform an operation not allowed by the security policy `PDF’” (SOLVED)
Posted by Alex On March 22, 2022

What program to open .docbook files (DocBook)
Posted by Alex On February 20, 2021