Tag: computer performance

How to speed up a VirtualBox virtual machine
Posted by Alex On August 15, 2023

Terrible VirtualBox disk performance (SOLVED)
Posted by Alex On August 15, 2023

How to move VirtualBox virtual machines to another drive or computer
Posted by Alex On August 15, 2023

How to increase the swap partition in Linux Mint and Ubuntu. How to create a Swap file in Linux
Posted by Alex On July 2, 2022

Swap file and swap partition in Arch Linux (BlackArch): what to choose and how to add Swap
Posted by Alex On July 1, 2022
How to clean up Windows 11 without additional programs
Posted by Alex On January 25, 2022

How to determine the type and speed of a USB port
Posted by Alex On November 28, 2021

Comparison of performance (data transfer rate) of OpenVPN over UDP and TCP
Posted by Alex On November 25, 2021

What happens if Linux runs out of RAM. Do I need a Swap file
Posted by Alex On November 20, 2021
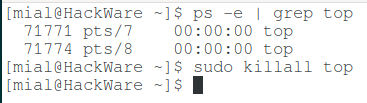
What are the differences and how to use the kill, pkill and killall commands
Posted by Alex On October 30, 2021